Product we created
Visit Operations Platform — eleven shipped surfaces, one source of truth. The visual walk and the design rationale behind every decision.
Visit Operations Platform is a vertical product. Every feature exists because a real human — scheduler, manager, clinician, sponsor — has a specific job and a specific frustration. The calendar canvas is the home base. Optimize Day shrinks a nurse's drive time with a 2-opt route optimizer. Smart Match books an RN, CRC, and investigator together with one click. Quick Book lets a scheduler book a visit without leaving the keyboard. Coverage Insights resolves time-off requests in batch. Audit records every change with an undo for bulk actions.
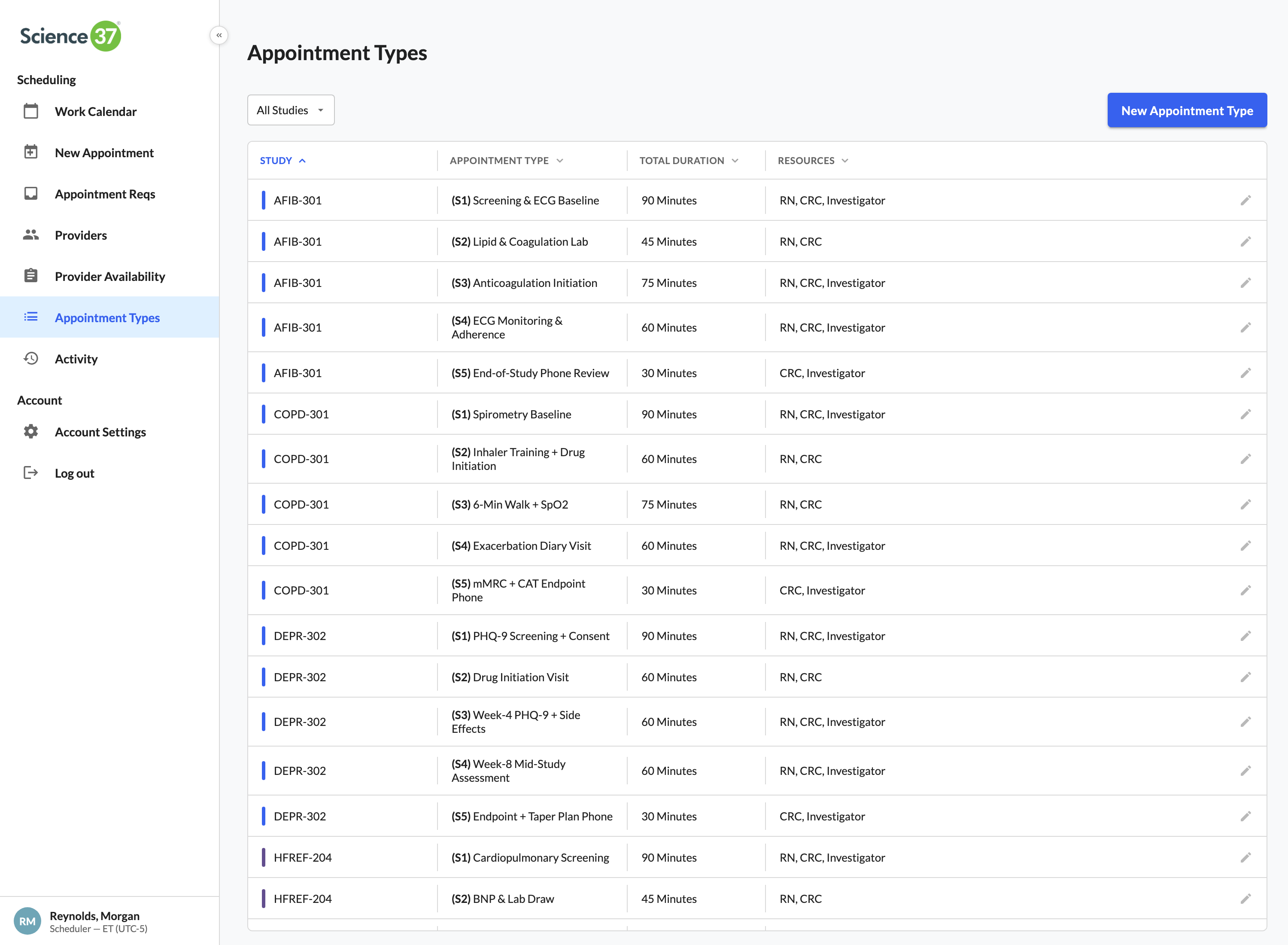
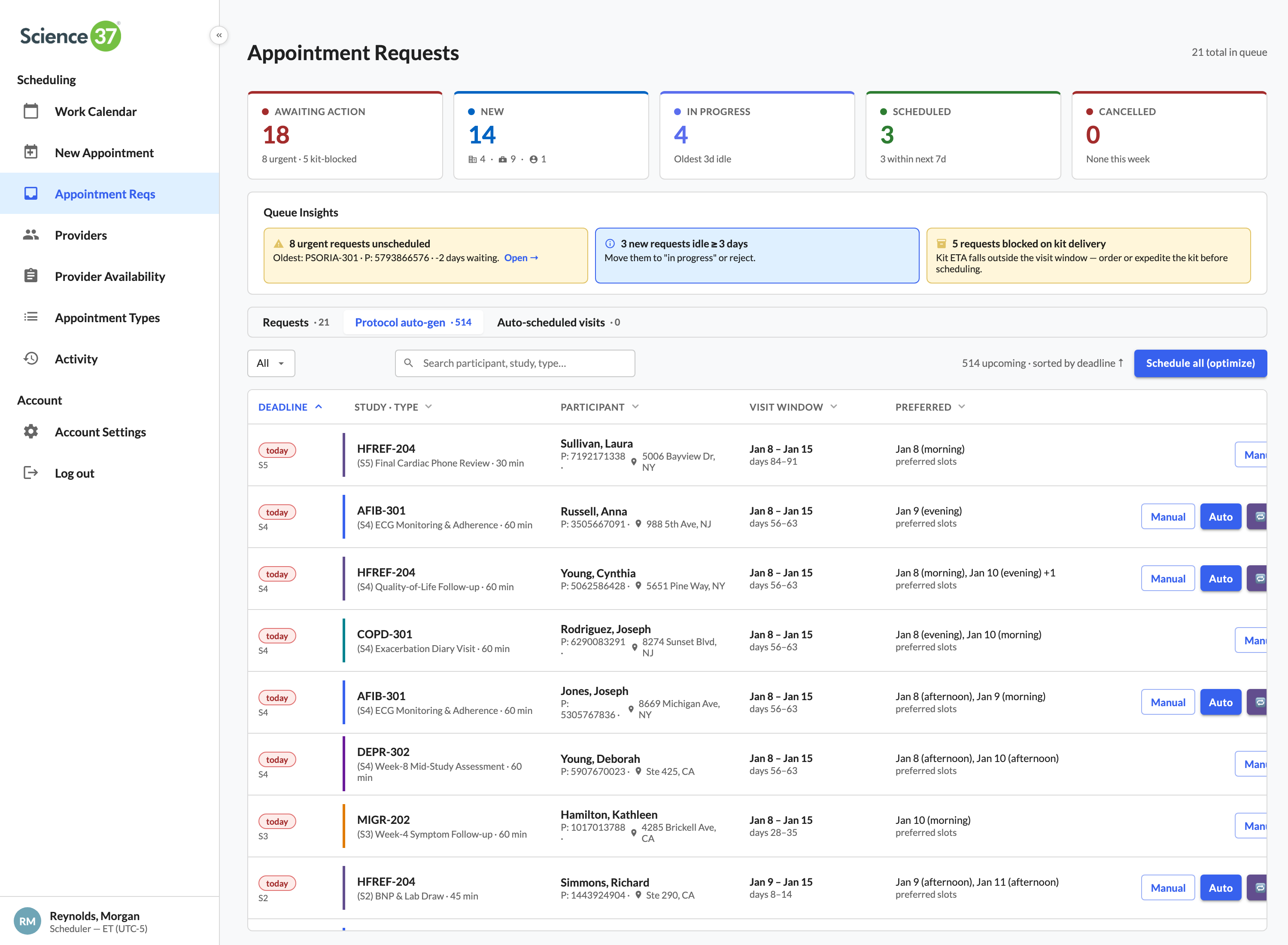
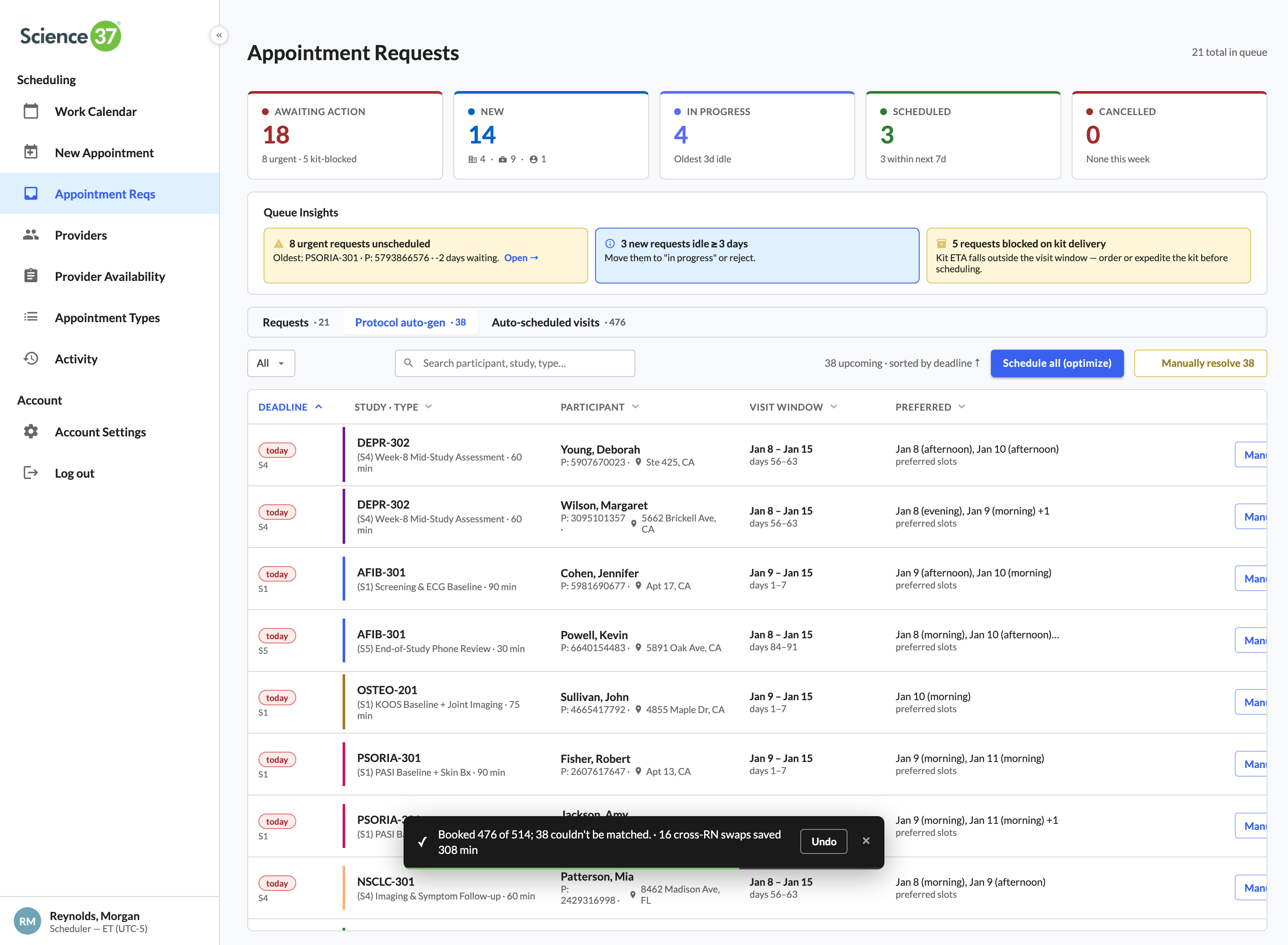
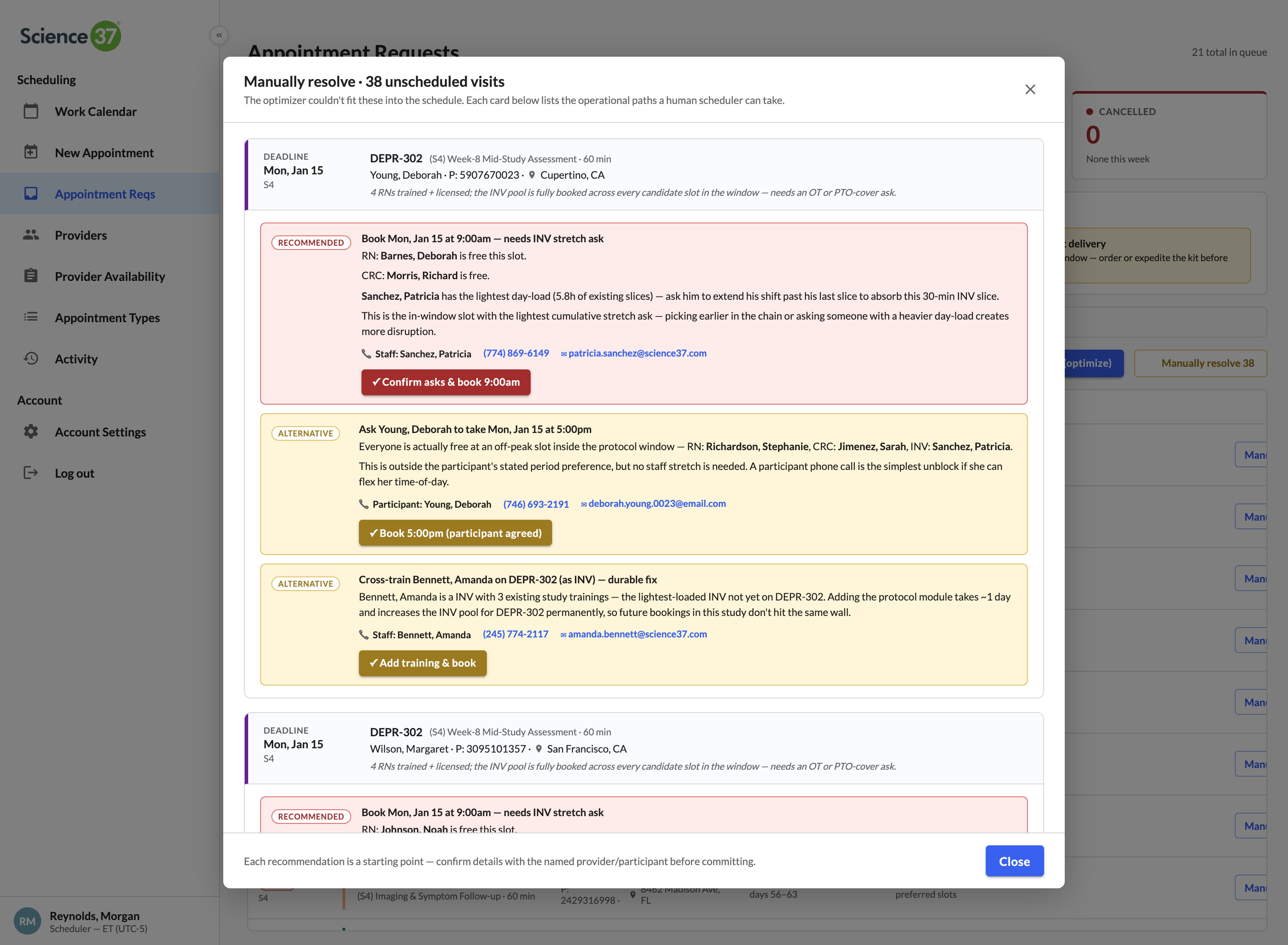
The full case study walks all eleven surfaces in narrative order — the calendar, the role timeline, optimize day, quick book, the new-appointment form, the request triage, smart-match panels, coverage insights, the roster, audit, and the appointment detail panel. Below: six of those surfaces summarized as cards, then the complete UI gallery, then the case-study PDF link.
One workspace for the entire scheduling team
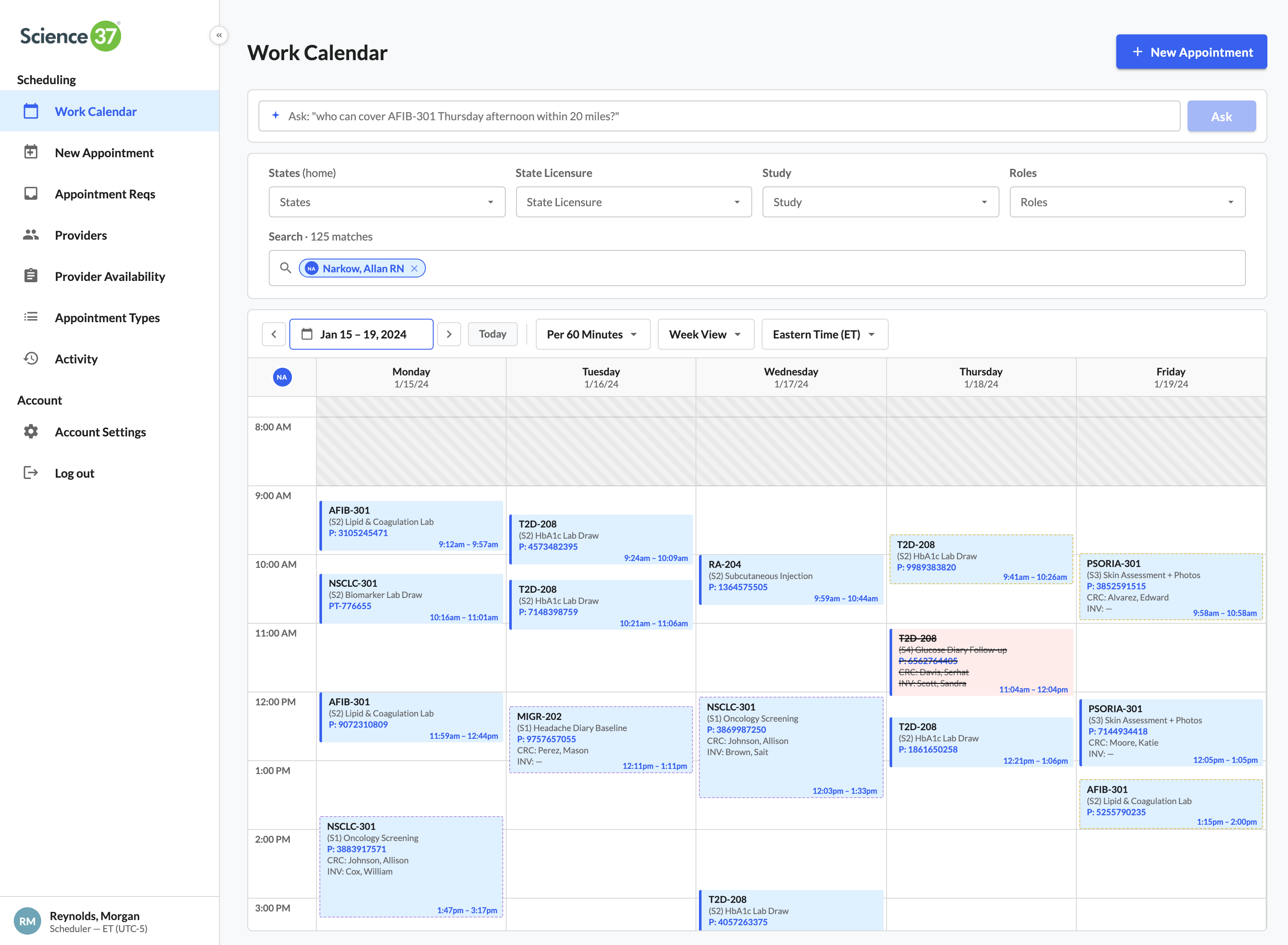
Filter first, focus second. Search across the full network, drop chips for provider / study / state / role, and the calendar collapses to just the work that matters this morning.
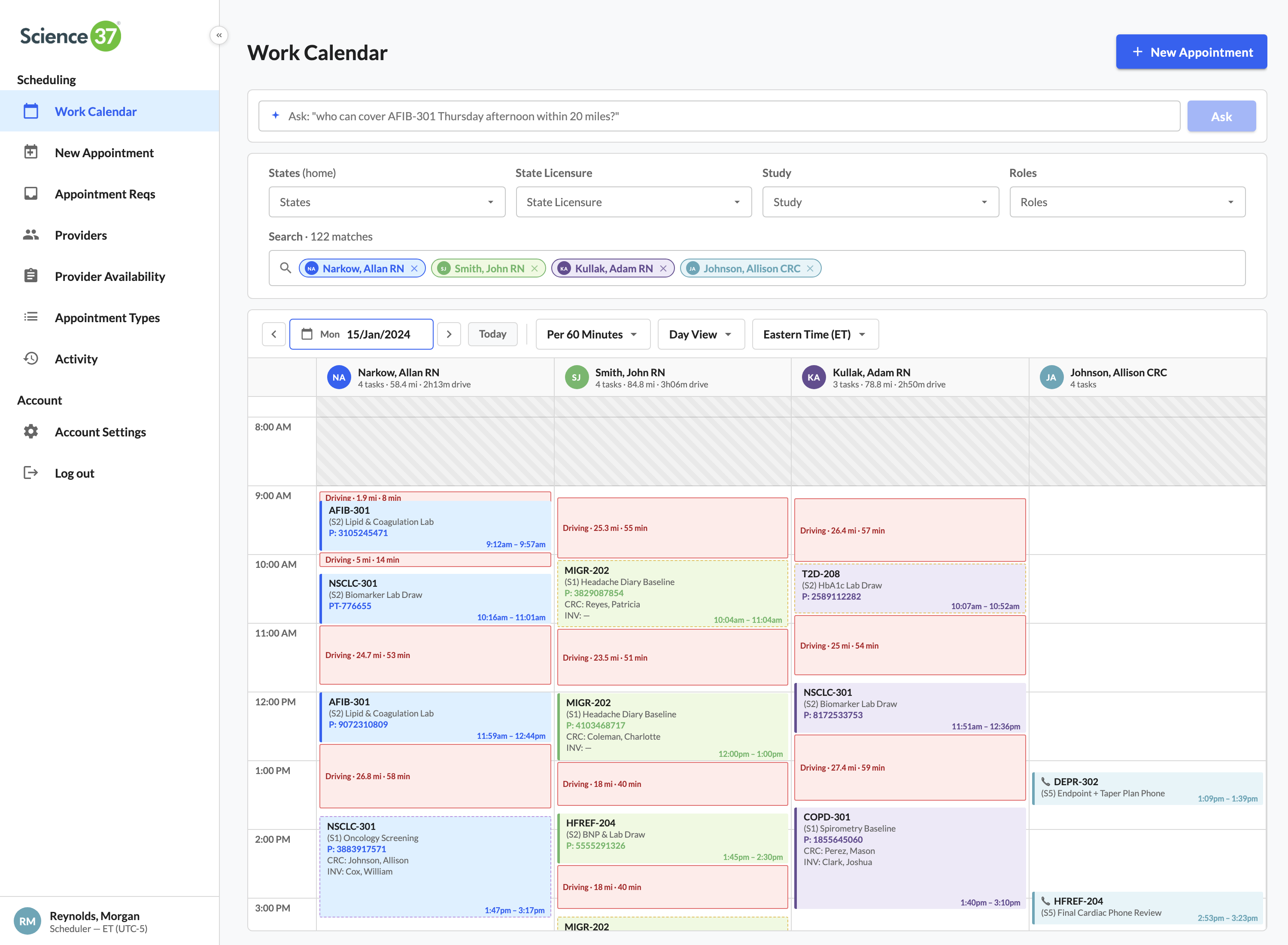
One timeline. Every role's actual minutes on every visit
An AFIB-301 screening is RN on-site 90 min, CRC dialing in for the middle 60, investigator for the final 30. The calendar shows each role's exact slice — not the whole appointment block.
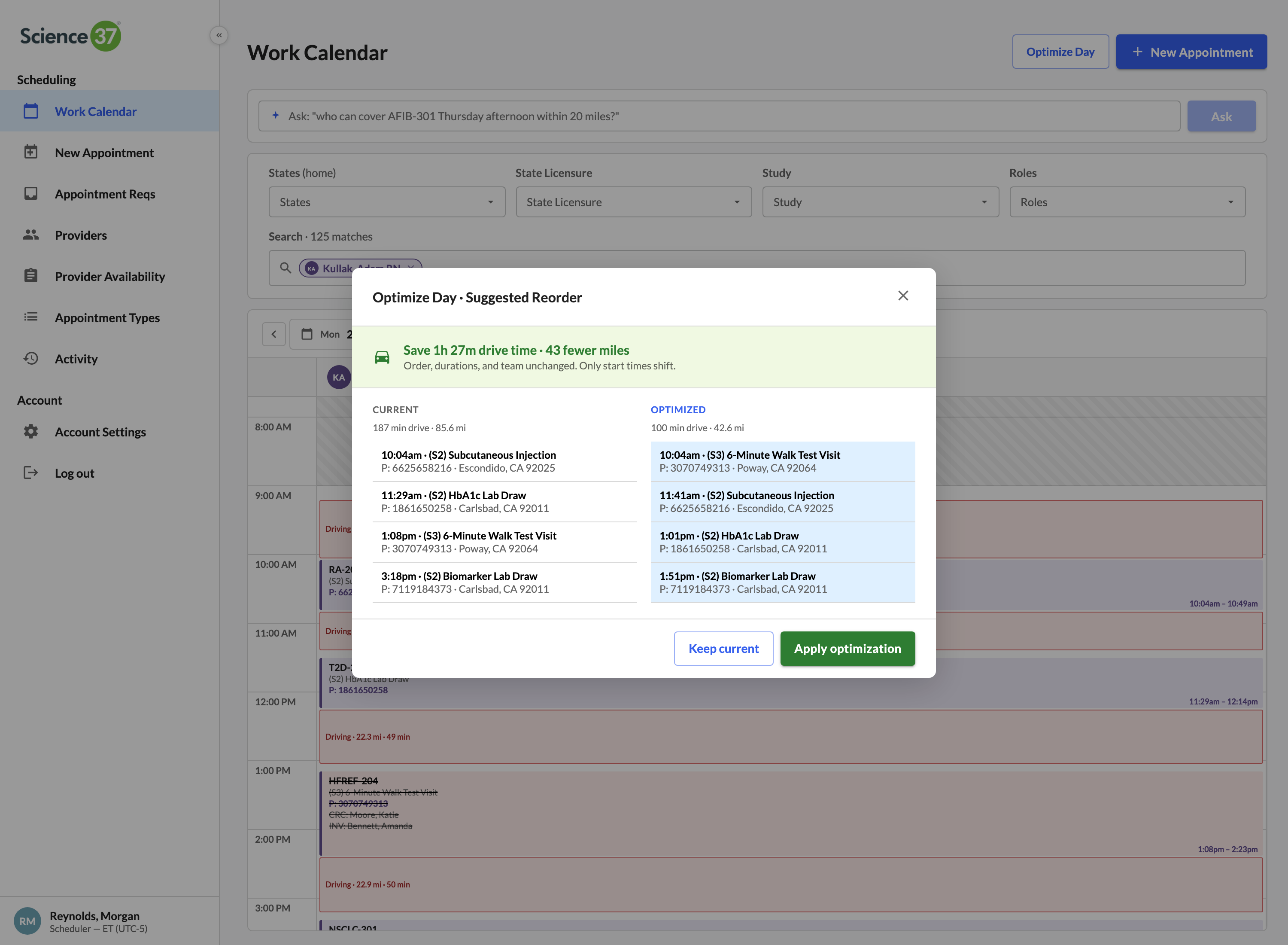
2-opt drive-time optimizer, per provider, per day
Treats a nurse's day as a Travelling Salesman instance anchored at her home. Nearest-neighbor seed, 2-opt local search, before/after diff. One click to accept the shorter route.
⌘K command palette — book without leaving the keyboard
Linear/Figma-style palette. Type a participant ID, study, and time. An appointment is created in seconds. Built because schedulers do dozens of bookings a day and slow point-and-click is a tax on throughput.
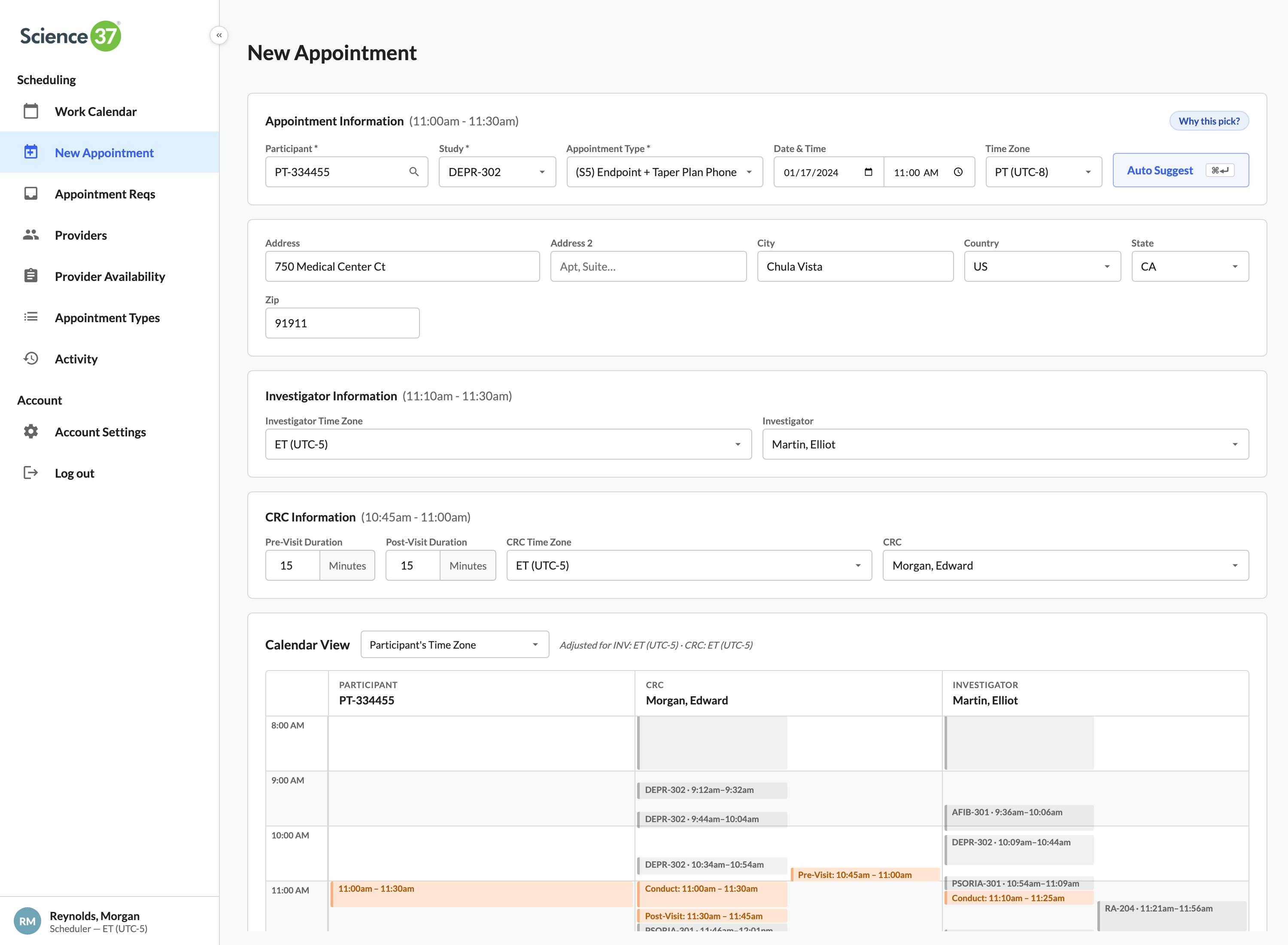
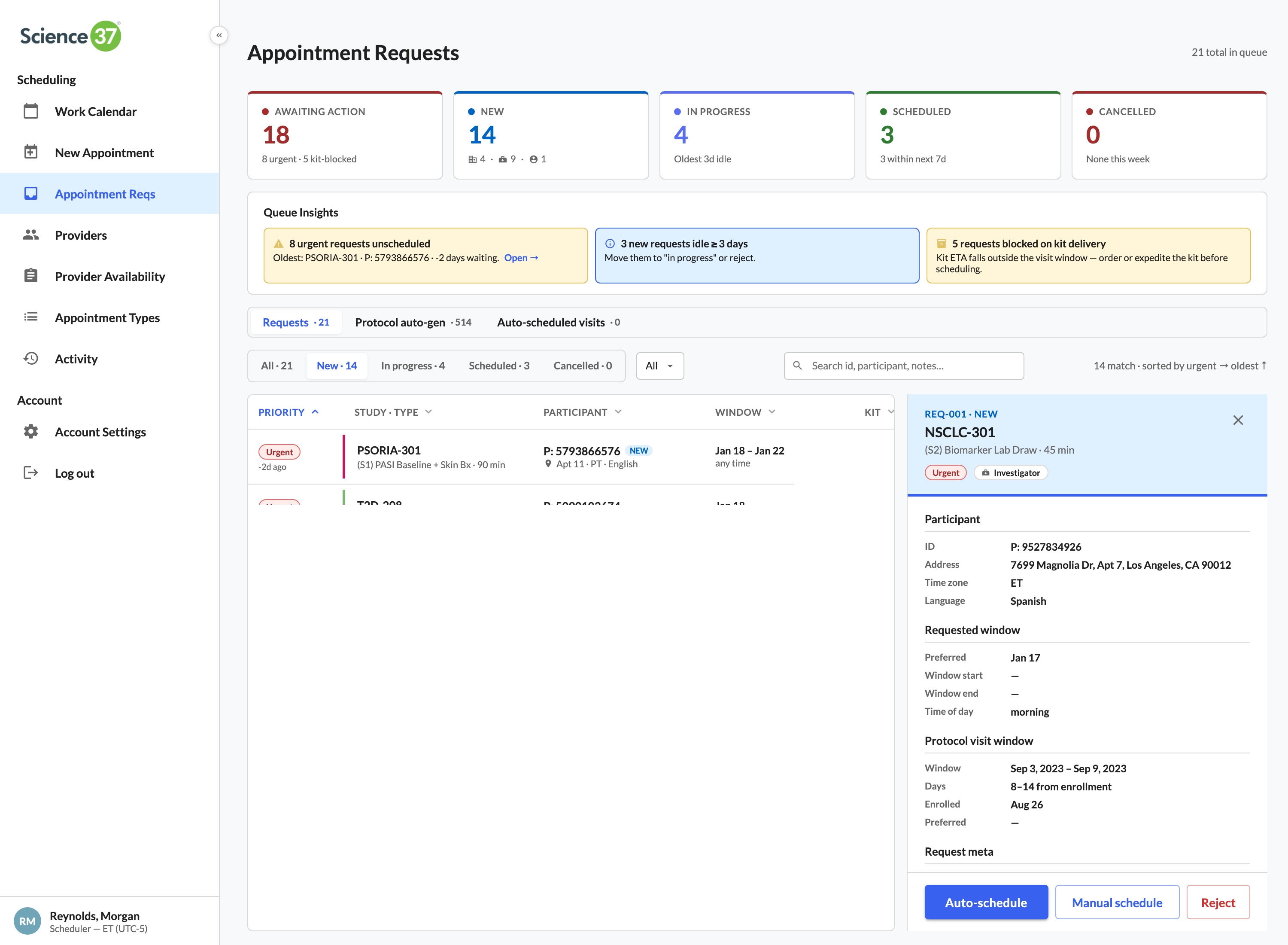
One click pairs the right RN, CRC, and investigator
The matching engine filters by study trained, state licensure, and slot availability — then ranks by drive distance from home to the participant. The scheduler sees the top match and the reasons, books all three in one click.
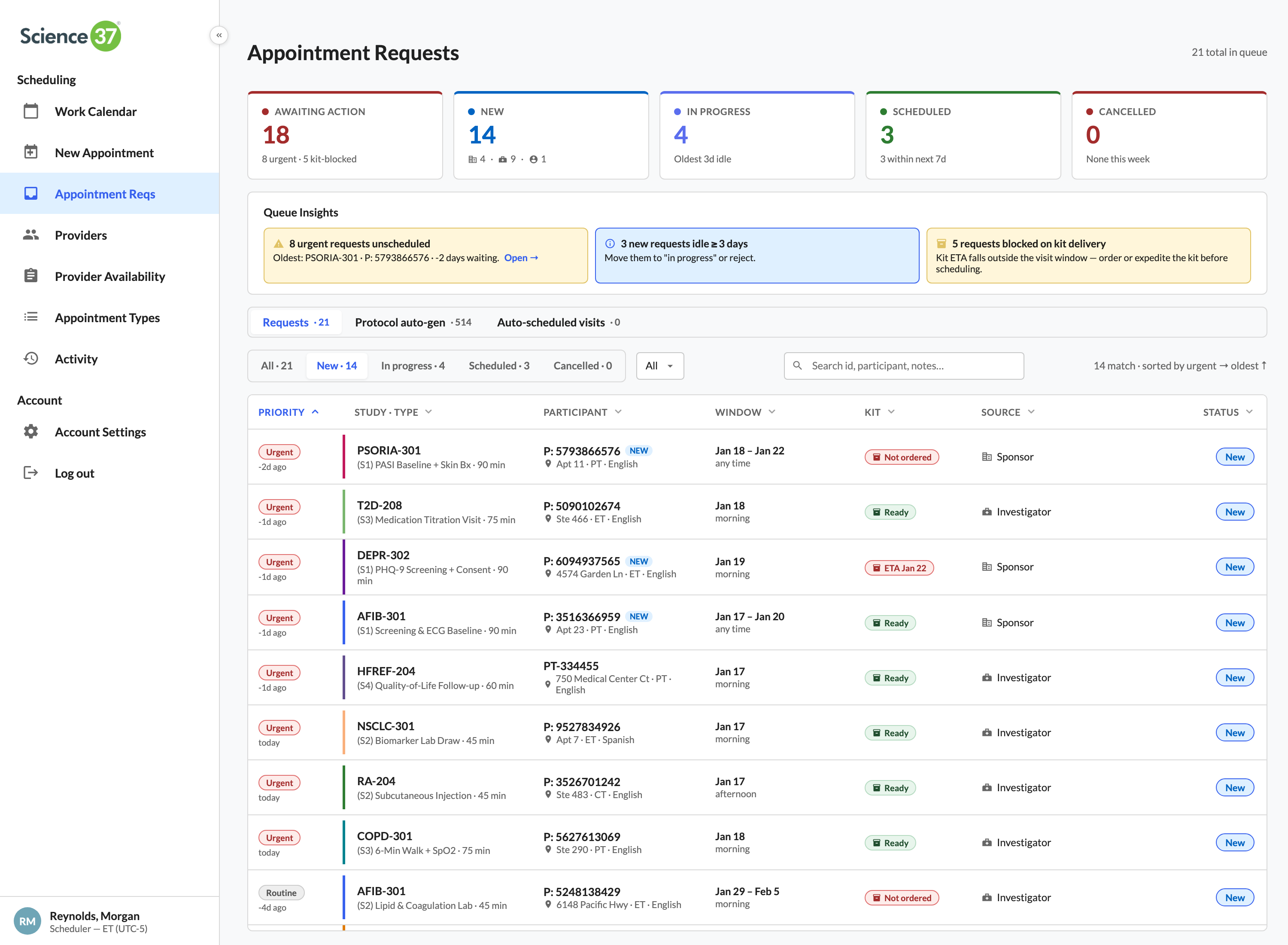
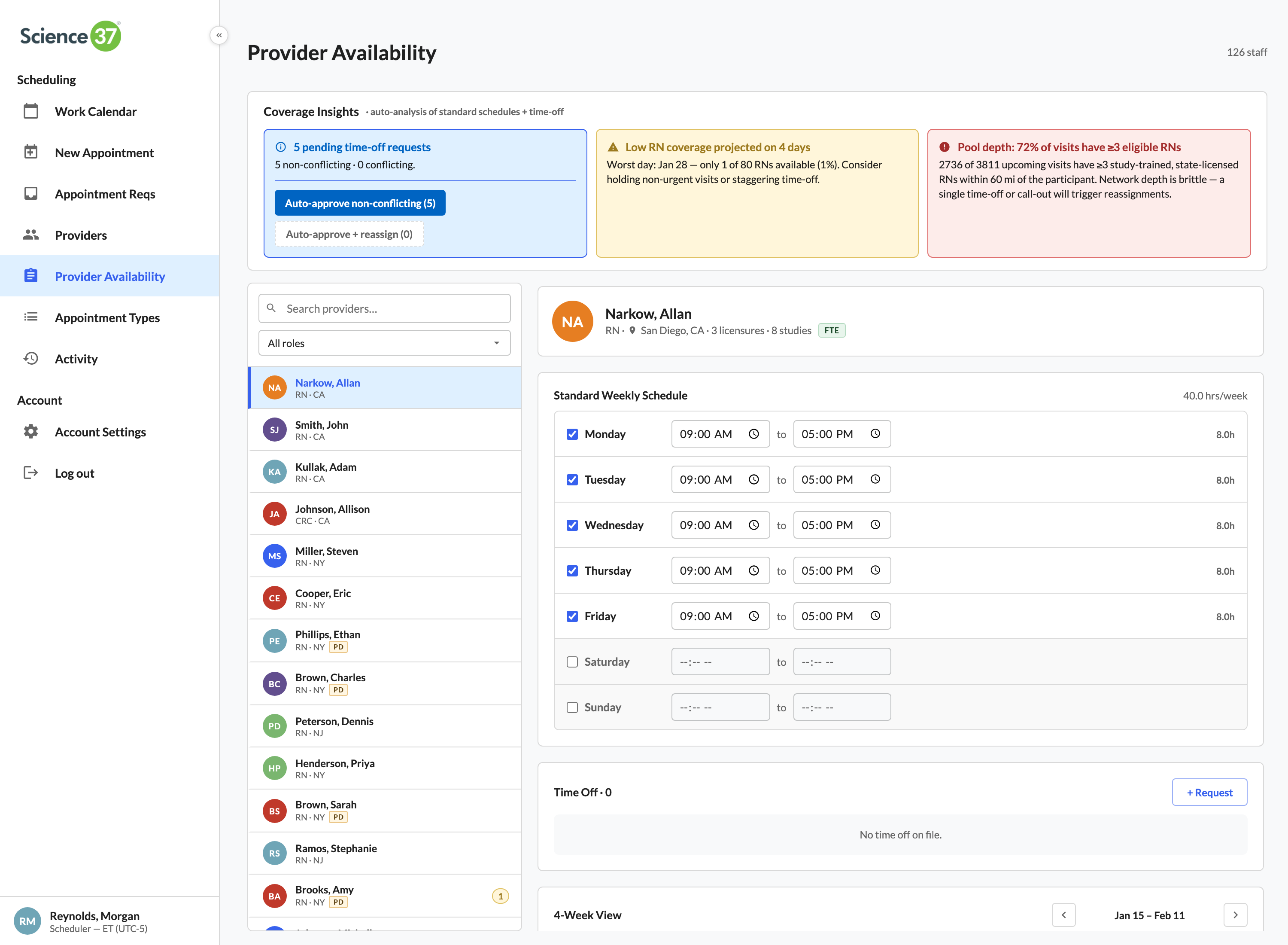
89 time-off requests, 87 resolved without scheduler legwork
Auto-classifies the queue: 65 have no coverage impact (one-click approve), 22 collide with confirmed visits but a nearby licensed RN can swap in (one-click reassign), 2 are blocking and require an explicit reschedule.
A walk through the twelve surfaces.
Click a thumbnail to open the full screenshot.